7.2 KiB
![]()
FreqAI
Introduction
FreqAI is a software designed to automate a variety of tasks associated with training a predictive machine learning model to generate market forecasts given a set of input features.
Features include:
- Self-adaptive retraining - Retrain models during live deployments to self-adapt to the market in a supervised manner
- Rapid feature engineering - Create large rich feature sets (10k+ features) based on simple user-created strategies
- High performance - Threading allows for adaptive model retraining on a separate thread (or on GPU if available) from model inferencing (prediction) and bot trade operations. Newest models and data are kept in RAM for rapid inferencing
- Realistic backtesting - Emulate self-adaptive training on historic data with a backtesting module that automates retraining
- Extensibility - The generalized and robust architecture allows for incorporating any machine learning library/method available in Python. Eight examples are currently available, including classifiers, regressors, and a convolutional neural network
- Smart outlier removal - Remove outliers from training and prediction data sets using a variety of outlier detection techniques
- Crash resilience - Store trained models to disk to make reloading from a crash fast and easy, and purge obsolete files for sustained dry/live runs
- Automatic data normalization - Normalize the data in a smart and statistically safe way
- Automatic data download - Compute timeranges for data downloads and update historic data (in live deployments)
- Cleaning of incoming data - Handle NaNs safely before training and model inferencing
- Dimensionality reduction - Reduce the size of the training data via Principal Component Analysis
- Deploying bot fleets - Set one bot to train models while a fleet of follower bots inference the models and handle trades
Quick start
The easiest way to quickly test FreqAI is to run it in dry mode with the following command:
freqtrade trade --config config_examples/config_freqai.example.json --strategy FreqaiExampleStrategy --freqaimodel LightGBMRegressor --strategy-path freqtrade/templates
You will see the boot-up process of automatic data downloading, followed by simultaneous training and trading.
An example strategy, prediction model, and config to use as a starting points can be found in
freqtrade/templates/FreqaiExampleStrategy.py, freqtrade/freqai/prediction_models/LightGBMRegressor.py, and
config_examples/config_freqai.example.json, respectively.
General approach
You provide FreqAI with a set of custom base indicators (the same way as in a typical Freqtrade strategy) as well as target values (labels). For each pair in the whitelist, FreqAI trains a model to predict the target values based on the input of custom indicators. The models are then consistently retrained, with a predetermined frequency, to adapt to market conditions. FreqAI offers the ability to both backtest strategies (emulating reality with periodic retraining on historic data) and deploy dry/live runs. In dry/live conditions, FreqAI can be set to constant retraining in a background thread to keep models as up to date as possible.
An overview of the algorithm, explaining the data processing pipeline and model usage, is shown below.
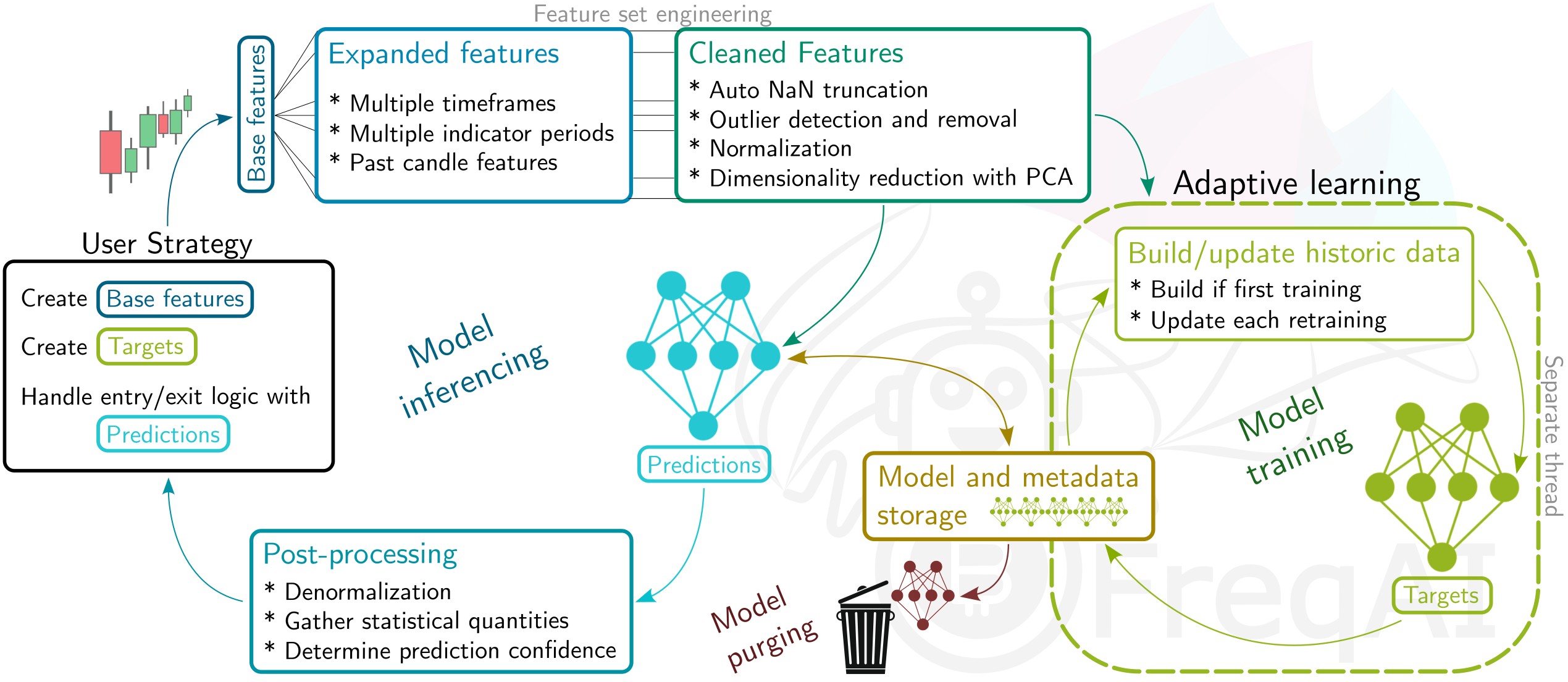
Important machine learning vocabulary
Features - the parameters, based on historic data, on which a model is trained. All features for a single candle is stored as a vector. In FreqAI, you build a feature data sets from anything you can construct in the strategy.
Labels - the target values that a model is trained toward. Each feature vector is associated with a single label that is defined by you within the strategy. These labels intentionally look into the future, and are not available to the model during dry/live/backtesting.
Training - the process of "teaching" the model to match the feature sets to the associated labels. Different types of models "learn" in different ways. More information about the different models can be found here.
Train data - a subset of the feature data set that is fed to the model during training. This data directly influences weight connections in the model.
Test data - a subset of the feature data set that is used to evaluate the performance of the model after training. This data does not influence nodal weights within the model.
Inferencing - the process of feeding a trained model new data on which it will make a prediction.
Install prerequisites
The normal Freqtrade install process will ask if you wish to install FreqAI dependencies. You should reply "yes" to this question if you wish to use FreqAI. If you did not reply yes, you can manually install these dependencies after the install with:
pip install -r requirements-freqai.txt
!!! Note Catboost will not be installed on arm devices (raspberry, Mac M1, ARM based VPS, ...), since it does not provide wheels for this platform.
Usage with docker
If you are using docker, a dedicated tag with FreqAI dependencies is available as :freqai. As such - you can replace the image line in your docker-compose file with image: freqtradeorg/freqtrade:develop_freqai. This image contains the regular FreqAI dependencies. Similar to native installs, Catboost will not be available on ARM based devices.
Common pitfalls
FreqAI cannot be combined with dynamic VolumePairlists (or any pairlist filter that adds and removes pairs dynamically).
This is for performance reasons - FreqAI relies on making quick predictions/retrains. To do this effectively,
it needs to download all the training data at the beginning of a dry/live instance. FreqAI stores and appends
new candles automatically for future retrains. This means that if new pairs arrive later in the dry run due to a volume pairlist, it will not have the data ready. However, FreqAI does work with the ShufflePairlist or a VolumePairlist which keeps the total pairlist constant (but reorders the pairs according to volume).
Credits
FreqAI is developed by a group of individuals who all contribute specific skillsets to the project.
Conception and software development: Robert Caulk @robcaulk
Theoretical brainstorming and data analysis: Elin Törnquist @th0rntwig
Code review and software architecture brainstorming: @xmatthias
Software development: Wagner Costa @wagnercosta
Beta testing and bug reporting: Stefan Gehring @bloodhunter4rc, @longyu, Andrew Robert Lawless @paranoidandy, Pascal Schmidt @smidelis, Ryan McMullan @smarmau, Juha Nykänen @suikula, Johan van der Vlugt @jooopiert, Richárd Józsa @richardjosza