19 KiB
Reinforcement Learning
!!! Note "Installation size"
Reinforcement learning dependencies include large packages such as torch, which should be explicitly requested during ./setup.sh -i by answering "y" to the question "Do you also want dependencies for freqai-rl (~700mb additional space required) [y/N]?".
Users who prefer docker should ensure they use the docker image appended with _freqairl.
Background and terminology
What is RL and why does FreqAI need it?
Reinforcement learning involves two important components, the agent and the training environment. During agent training, the agent moves through historical data candle by candle, always making 1 of a set of actions: Long entry, long exit, short entry, short exit, neutral). During this training process, the environment tracks the performance of these actions and rewards the agent according to a custom user made calculate_reward() (here we offer a default reward for users to build on if they wish details here). The reward is used to train weights in a neural network.
A second important component of the FreqAI RL implementation is the use of state information. State information is fed into the network at each step, including current profit, current position, and current trade duration. These are used to train the agent in the training environment, and to reinforce the agent in dry/live (this functionality is not available in backtesting). FreqAI + Freqtrade is a perfect match for this reinforcing mechanism since this information is readily available in live deployments.
Reinforcement learning is a natural progression for FreqAI, since it adds a new layer of adaptivity and market reactivity that Classifiers and Regressors cannot match. However, Classifiers and Regressors have strengths that RL does not have such as robust predictions. Improperly trained RL agents may find "cheats" and "tricks" to maximize reward without actually winning any trades. For this reason, RL is more complex and demands a higher level of understanding than typical Classifiers and Regressors.
The RL interface
With the current framework, we aim to expose the training environment via the common "prediction model" file, which is a user inherited BaseReinforcementLearner object (e.g. freqai/prediction_models/ReinforcementLearner). Inside this user class, the RL environment is available and customized via MyRLEnv as shown below.
We envision the majority of users focusing their effort on creative design of the calculate_reward() function details here, while leaving the rest of the environment untouched. Other users may not touch the environment at all, and they will only play with the configuration settings and the powerful feature engineering that already exists in FreqAI. Meanwhile, we enable advanced users to create their own model classes entirely.
The framework is built on stable_baselines3 (torch) and OpenAI gym for the base environment class. But generally speaking, the model class is well isolated. Thus, the addition of competing libraries can be easily integrated into the existing framework. For the environment, it is inheriting from gym.env which means that it is necessary to write an entirely new environment in order to switch to a different library.
Important considerations
As explained above, the agent is "trained" in an artificial trading "environment". In our case, that environment may seem quite similar to a real Freqtrade backtesting environment, but it is NOT. In fact, the RL training environment is much more simplified. It does not incorporate any of the complicated strategy logic, such as callbacks like custom_exit, custom_stoploss, leverage controls, etc. The RL environment is instead a very "raw" representation of the true market, where the agent has free-will to learn the policy (read: stoploss, take profit, etc.) which is enforced by the calculate_reward(). Thus, it is important to consider that the agent training environment is not identical to the real world.
Running Reinforcement Learning
Setting up and running a Reinforcement Learning model is the same as running a Regressor or Classifier. The same two flags, --freqaimodel and --strategy, must be defined on the command line:
freqtrade trade --freqaimodel ReinforcementLearner --strategy MyRLStrategy --config config.json
where ReinforcementLearner will use the templated ReinforcementLearner from freqai/prediction_models/ReinforcementLearner (or a custom user defined one located in user_data/freqaimodels). The strategy, on the other hand, follows the same base feature engineering with populate_any_indicators as a typical Regressor:
def populate_any_indicators(
self, pair, df, tf, informative=None, set_generalized_indicators=False
):
if informative is None:
informative = self.dp.get_pair_dataframe(pair, tf)
# first loop is automatically duplicating indicators for time periods
for t in self.freqai_info["feature_parameters"]["indicator_periods_candles"]:
t = int(t)
informative[f"%-{pair}rsi-period_{t}"] = ta.RSI(informative, timeperiod=t)
informative[f"%-{pair}mfi-period_{t}"] = ta.MFI(informative, timeperiod=t)
informative[f"%-{pair}adx-period_{t}"] = ta.ADX(informative, window=t)
# The following raw price values are necessary for RL models
informative[f"%-{pair}raw_close"] = informative["close"]
informative[f"%-{pair}raw_open"] = informative["open"]
informative[f"%-{pair}raw_high"] = informative["high"]
informative[f"%-{pair}raw_low"] = informative["low"]
indicators = [col for col in informative if col.startswith("%")]
# This loop duplicates and shifts all indicators to add a sense of recency to data
for n in range(self.freqai_info["feature_parameters"]["include_shifted_candles"] + 1):
if n == 0:
continue
informative_shift = informative[indicators].shift(n)
informative_shift = informative_shift.add_suffix("_shift-" + str(n))
informative = pd.concat((informative, informative_shift), axis=1)
df = merge_informative_pair(df, informative, self.config["timeframe"], tf, ffill=True)
skip_columns = [
(s + "_" + tf) for s in ["date", "open", "high", "low", "close", "volume"]
]
df = df.drop(columns=skip_columns)
# Add generalized indicators here (because in live, it will call this
# function to populate indicators during training). Notice how we ensure not to
# add them multiple times
if set_generalized_indicators:
# For RL, there are no direct targets to set. This is filler (neutral)
# until the agent sends an action.
df["&-action"] = 0
return df
Most of the function remains the same as for typical Regressors, however, the function above shows how the strategy must pass the raw price data to the agent so that it has access to raw OHLCV in the training environment:
# The following features are necessary for RL models
informative[f"%-{pair}raw_close"] = informative["close"]
informative[f"%-{pair}raw_open"] = informative["open"]
informative[f"%-{pair}raw_high"] = informative["high"]
informative[f"%-{pair}raw_low"] = informative["low"]
Finally, there is no explicit "label" to make - instead it is necessary to assign the &-action column which will contain the agent's actions when accessed in populate_entry/exit_trends(). In the present example, the neutral action to 0. This value should align with the environment used. FreqAI provides two environments, both use 0 as the neutral action.
After users realize there are no labels to set, they will soon understand that the agent is making its "own" entry and exit decisions. This makes strategy construction rather simple. The entry and exit signals come from the agent in the form of an integer - which are used directly to decide entries and exits in the strategy:
def populate_entry_trend(self, df: DataFrame, metadata: dict) -> DataFrame:
enter_long_conditions = [df["do_predict"] == 1, df["&-action"] == 1]
if enter_long_conditions:
df.loc[
reduce(lambda x, y: x & y, enter_long_conditions), ["enter_long", "enter_tag"]
] = (1, "long")
enter_short_conditions = [df["do_predict"] == 1, df["&-action"] == 3]
if enter_short_conditions:
df.loc[
reduce(lambda x, y: x & y, enter_short_conditions), ["enter_short", "enter_tag"]
] = (1, "short")
return df
def populate_exit_trend(self, df: DataFrame, metadata: dict) -> DataFrame:
exit_long_conditions = [df["do_predict"] == 1, df["&-action"] == 2]
if exit_long_conditions:
df.loc[reduce(lambda x, y: x & y, exit_long_conditions), "exit_long"] = 1
exit_short_conditions = [df["do_predict"] == 1, df["&-action"] == 4]
if exit_short_conditions:
df.loc[reduce(lambda x, y: x & y, exit_short_conditions), "exit_short"] = 1
return df
It is important to consider that &-action depends on which environment they choose to use. The example above shows 5 actions, where 0 is neutral, 1 is enter long, 2 is exit long, 3 is enter short and 4 is exit short.
Configuring the Reinforcement Learner
In order to configure the Reinforcement Learner the following dictionary must exist in the freqai config:
"rl_config": {
"train_cycles": 25,
"add_state_info": true,
"max_trade_duration_candles": 300,
"max_training_drawdown_pct": 0.02,
"cpu_count": 8,
"model_type": "PPO",
"policy_type": "MlpPolicy",
"model_reward_parameters": {
"rr": 1,
"profit_aim": 0.025
}
}
Parameter details can be found here, but in general the train_cycles decides how many times the agent should cycle through the candle data in its artificial environment to train weights in the model. model_type is a string which selects one of the available models in stable_baselines(external link).
!!! Note
If you would like to experiment with continual_learning, then you should set that value to true in the main freqai configuration dictionary. This will tell the Reinforcement Learning library to continue training new models from the final state of previous models, instead of retraining new models from scratch each time a retrain is initiated.
!!! Note
Remember that the general model_training_parameters dictionary should contain all the model hyperparameter customizations for the particular model_type. For example, PPO parameters can be found here.
Creating a custom reward function
As you begin to modify the strategy and the prediction model, you will quickly realize some important differences between the Reinforcement Learner and the Regressors/Classifiers. Firstly, the strategy does not set a target value (no labels!). Instead, you set the calculate_reward() function inside the MyRLEnv class (see below). A default calculate_reward() is provided inside prediction_models/ReinforcementLearner.py to demonstrate the necessary building blocks for creating rewards, but users are encouraged to create their own custom reinforcement learning model class (see below) and save it to user_data/freqaimodels. It is inside the calculate_reward() where creative theories about the market can be expressed. For example, you can reward your agent when it makes a winning trade, and penalize the agent when it makes a losing trade. Or perhaps, you wish to reward the agent for entering trades, and penalize the agent for sitting in trades too long. Below we show examples of how these rewards are all calculated:
from freqtrade.freqai.prediction_models.ReinforcementLearner import ReinforcementLearner
from freqtrade.freqai.RL.Base5ActionRLEnv import Actions, Base5ActionRLEnv, Positions
class MyCoolRLModel(ReinforcementLearner):
"""
User created RL prediction model.
Save this file to `freqtrade/user_data/freqaimodels`
then use it with:
freqtrade trade --freqaimodel MyCoolRLModel --config config.json --strategy SomeCoolStrat
Here the users can override any of the functions
available in the `IFreqaiModel` inheritance tree. Most importantly for RL, this
is where the user overrides `MyRLEnv` (see below), to define custom
`calculate_reward()` function, or to override any other parts of the environment.
This class also allows users to override any other part of the IFreqaiModel tree.
For example, the user can override `def fit()` or `def train()` or `def predict()`
to take fine-tuned control over these processes.
Another common override may be `def data_cleaning_predict()` where the user can
take fine-tuned control over the data handling pipeline.
"""
class MyRLEnv(Base5ActionRLEnv):
"""
User made custom environment. This class inherits from BaseEnvironment and gym.env.
Users can override any functions from those parent classes. Here is an example
of a user customized `calculate_reward()` function.
"""
def calculate_reward(self, action: int) -> float:
# first, penalize if the action is not valid
if not self._is_valid(action):
return -2
pnl = self.get_unrealized_profit()
factor = 100
# reward agent for entering trades
if action in (Actions.Long_enter.value, Actions.Short_enter.value) \
and self._position == Positions.Neutral:
return 25
# discourage agent from not entering trades
if action == Actions.Neutral.value and self._position == Positions.Neutral:
return -1
max_trade_duration = self.rl_config.get('max_trade_duration_candles', 300)
trade_duration = self._current_tick - self._last_trade_tick
if trade_duration <= max_trade_duration:
factor *= 1.5
elif trade_duration > max_trade_duration:
factor *= 0.5
# discourage sitting in position
if self._position in (Positions.Short, Positions.Long) and \
action == Actions.Neutral.value:
return -1 * trade_duration / max_trade_duration
# close long
if action == Actions.Long_exit.value and self._position == Positions.Long:
if pnl > self.profit_aim * self.rr:
factor *= self.rl_config['model_reward_parameters'].get('win_reward_factor', 2)
return float(pnl * factor)
# close short
if action == Actions.Short_exit.value and self._position == Positions.Short:
if pnl > self.profit_aim * self.rr:
factor *= self.rl_config['model_reward_parameters'].get('win_reward_factor', 2)
return float(pnl * factor)
return 0.
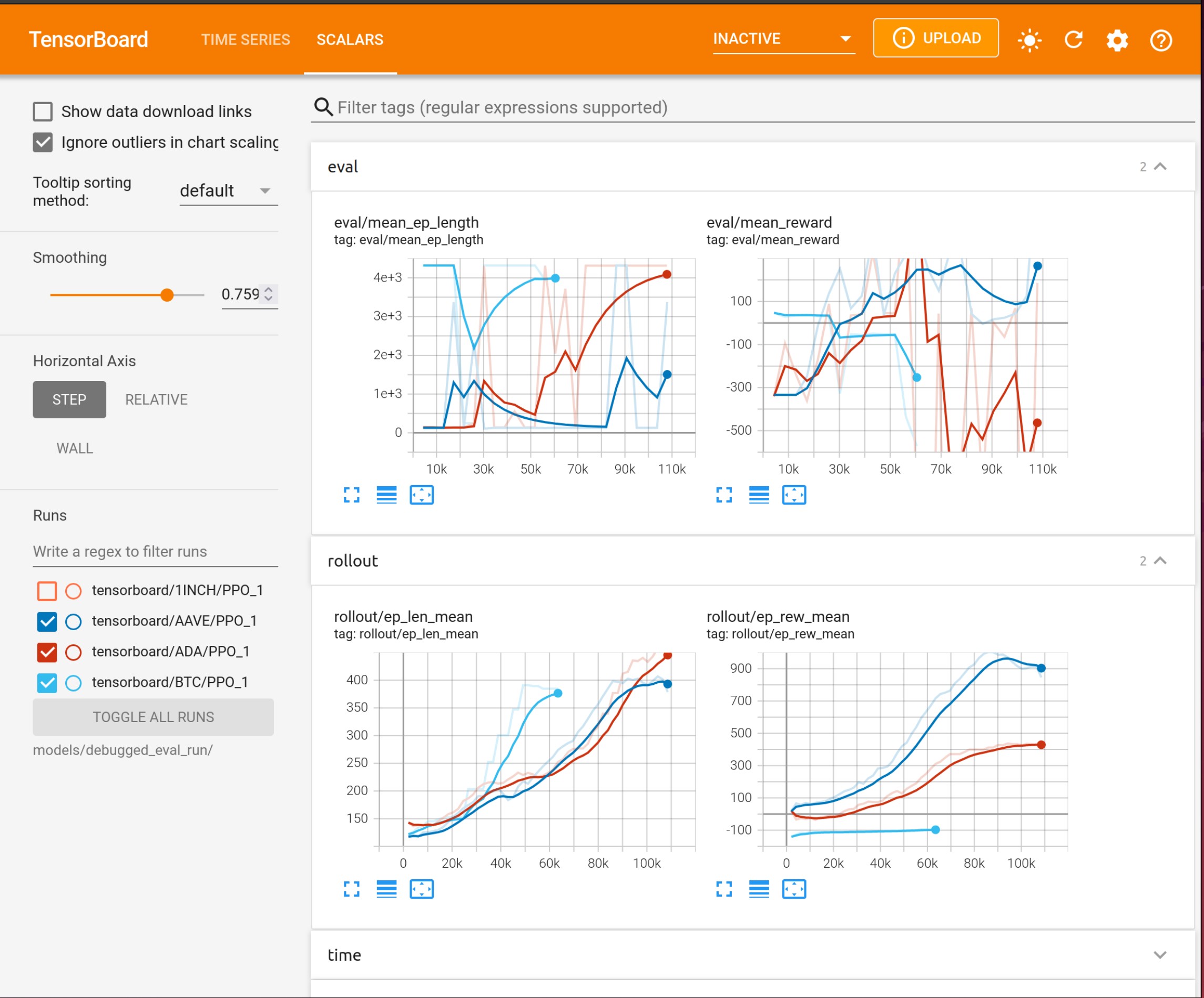
Using Tensorboard
Reinforcement Learning models benefit from tracking training metrics. FreqAI has integrated Tensorboard to allow users to track training and evaluation performance across all coins and across all retrainings. Tensorboard is activated via the following command:
cd freqtrade
tensorboard --logdir user_data/models/unique-id
where unique-id is the identifier set in the freqai configuration file. This command must be run in a separate shell to view the output in their browser at 127.0.0.1:6006 (6006 is the default port used by Tensorboard).
Custom logging
FreqAI also provides a built in episodic summary logger called self.tensorboard_log for adding custom information to the Tensorboard log. By default, this function is already called once per step inside the environment to record the agent actions. All values accumulated for all steps in a single episode are reported at the conclusion of each episode, followed by a full reset of all metrics to 0 in preparation for the subsequent episode.
self.tensorboard_log can also be used anywhere inside the environment, for example, it can be added to the calculate_reward function to collect more detailed information about how often various parts of the reward were called:
class MyRLEnv(Base5ActionRLEnv):
"""
User made custom environment. This class inherits from BaseEnvironment and gym.env.
Users can override any functions from those parent classes. Here is an example
of a user customized `calculate_reward()` function.
"""
def calculate_reward(self, action: int) -> float:
if not self._is_valid(action):
self.tensorboard_log("is_valid")
return -2
!!! Note
The self.tensorboard_log() function is designed for tracking incremented objects only i.e. events, actions inside the training environment. If the event of interest is a float, the float can be passed as the second argument e.g. self.tensorboard_log("float_metric1", 0.23) would add 0.23 to float_metric. In this case you can also disable incrementing using inc=False parameter.
Choosing a base environment
FreqAI provides two base environments, Base4ActionEnvironment and Base5ActionEnvironment. As the names imply, the environments are customized for agents that can select from 4 or 5 actions. In the Base4ActionEnvironment, the agent can enter long, enter short, hold neutral, or exit position. Meanwhile, in the Base5ActionEnvironment, the agent has the same actions as Base4, but instead of a single exit action, it separates exit long and exit short. The main changes stemming from the environment selection include:
- the actions available in the
calculate_reward - the actions consumed by the user strategy
Both of the FreqAI provided environments inherit from an action/position agnostic environment object called the BaseEnvironment, which contains all shared logic. The architecture is designed to be easily customized. The simplest customization is the calculate_reward() (see details here). However, the customizations can be further extended into any of the functions inside the environment. You can do this by simply overriding those functions inside your MyRLEnv in the prediction model file. Or for more advanced customizations, it is encouraged to create an entirely new environment inherited from BaseEnvironment.
!!! Note
FreqAI does not provide by default, a long-only training environment. However, creating one should be as simple as copy-pasting one of the built in environments and removing the short actions (and all associated references to those).